Scrapy 设置中 CONCURRENT_REQUESTS 及 DOWNLOAD_DELAY 等几个相关参数的作用
Contents
Scrapy的默认设置中,有几个关于并发请求及下载延迟的参数,这几个参数的设置,既影响请求效率,同时关乎对方服务器的压力大小。
相关的几个参数:
-
CONCURRENT_REQUESTS
默认值:16
Scrapy下载器发送的最大并发请求数。 -
CONCURRENT_REQUESTS_PER_DOMAIN
默认值:8
针对某一个域名的最大并发请求数。 -
CONCURRENT_REQUESTS_PER_IP
默认值:0
针对某一ip的最大并发请求数。如果此项非0的话,它的优先级高于CONCURRENT_REQUESTS_PER_DOMAIN。也就是说此时的并发数量限制是基于ip的,而非域名。
同时这个设置也会影响到DOWNLOAD_DELAY,如果CONCURRENT_REQUESTS_PER_IP非0,下载延迟会基于ip,而非域名。 -
DOWNLOAD_DELAY
默认值:0
每个请求间的下载延迟,单位为秒。同时受RANDOMIZE_DOWNLOAD_DELAY参数(默认开启)影响,下载延迟并不会是设定的固定值,而是在 0.5*DOWNLOAD_DELAY~1.5*DOWNLOAD_DELAY区间内。
默认是针对同一域名的每个请求设置DELAY,如果CONCURRENT_REQUESTS_PER_DOMAIN非0,下载延迟会基于ip,而非域名。
这里通过实验的方式,验证这几个参数的表现,以及同时设置某几个参数的影响。为了能直观准确的看到请求时间差,全程将RANDOMIZE_DOWNLOAD_DELAY设置为False,也就是固定下载延迟,而非在区间内波动。
准备工作
使用flask写一个简易的服务端程序,同时在两台机器上运行。
|
|
创建一个scrapy项目,其中spider脚本如下,在请求队列中均匀分布两个ip的请求:
|
|
实验验证
根据上文,CONCURRENT_REQUESTS_PER_DOMAIN和CONCURRENT_REQUESTS_PER_IP两个参数是覆盖关系,所以这里只以其中任何一个作为参考即可,这里选择CONCURRENT_REQUESTS_PER_DOMAIN。
只单独设置并发数CONCURRENT_REQUESTS或者CONCURRENT_REQUESTS_PER_DOMAIN
|
|
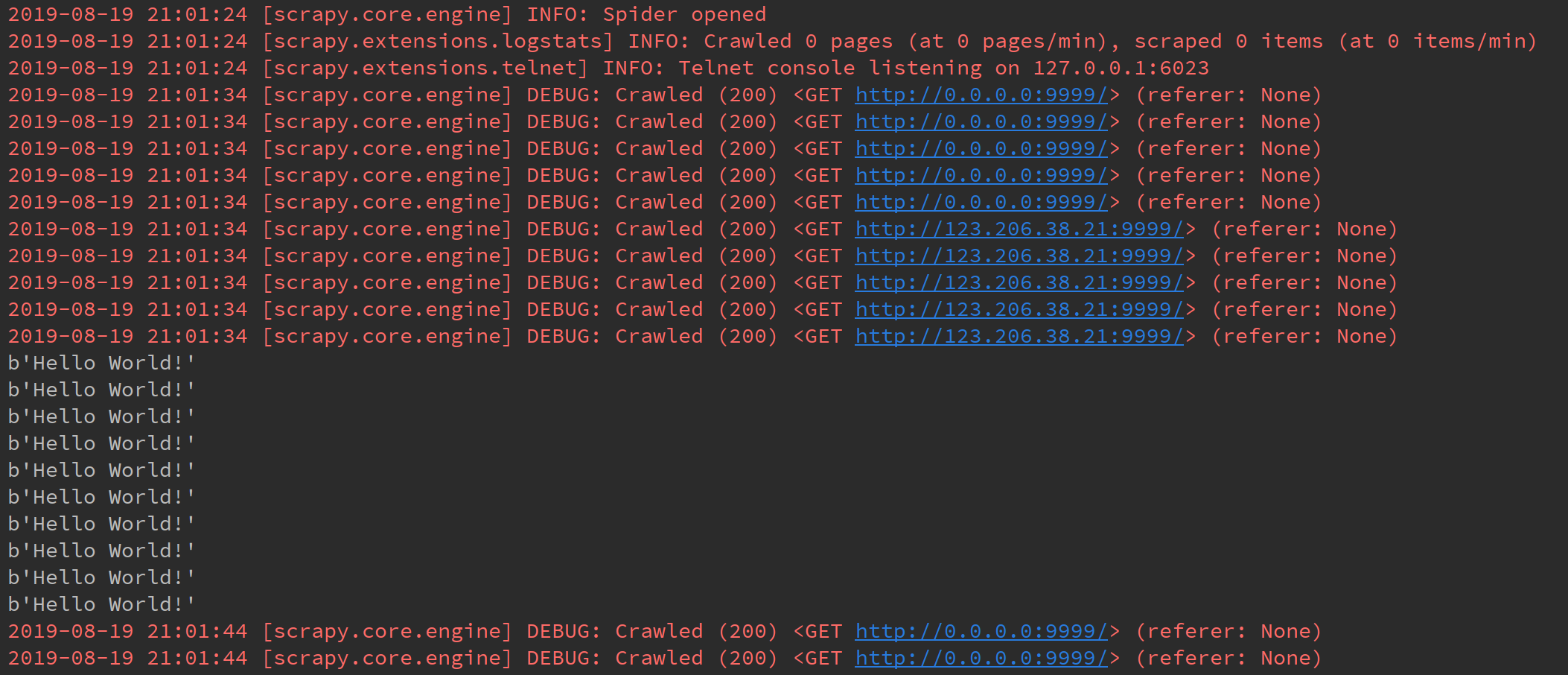
或者
|
|
结果显而易见,CONCURRENT_REQUESTS限制了总并发数,CONCURRENT_REQUESTS_PER_DOMAIN分别对单个域名的并发数起到了限制。
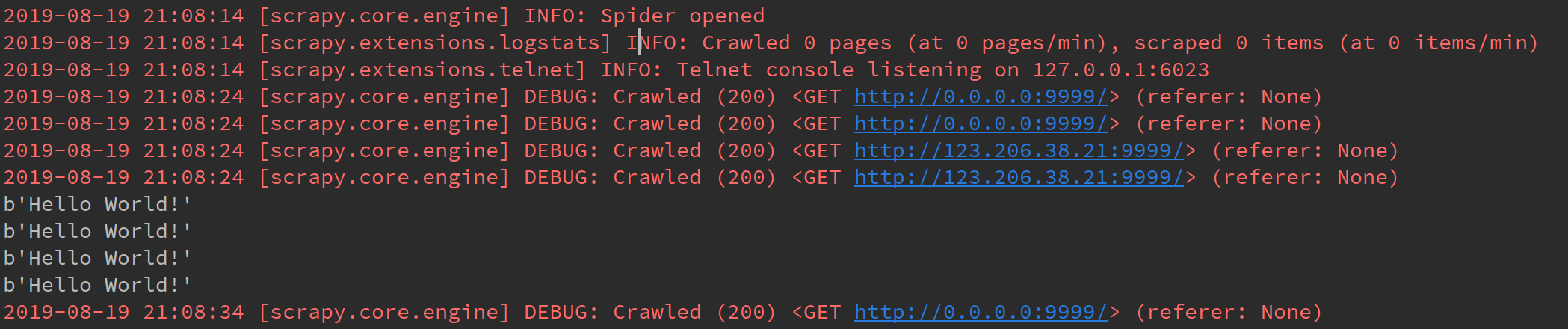
同时设置CONCURRENT_REQUESTS和CONCURRENT_REQUESTS_PER_DOMAIN
|
|
在同时设置CONCURRENT_REQUESTS和CONCURRENT_REQUESTS_PER_DOMAIN时,两者不存在覆盖关系,而是共同对并发数起到了限制,两者的交集决定了最大并发数。
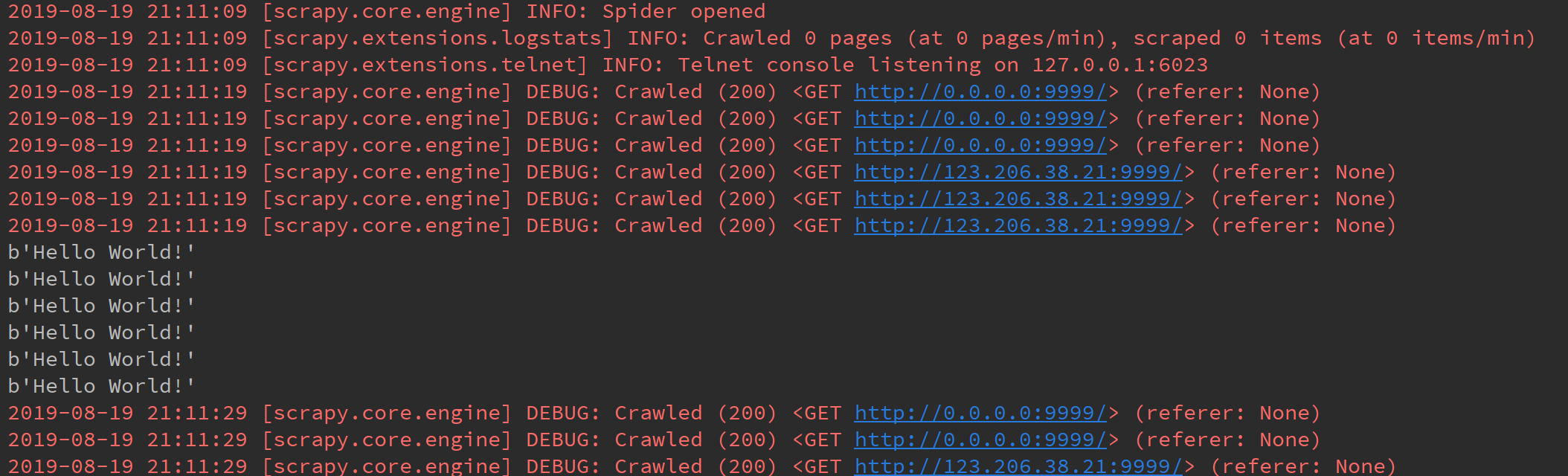
不开启并发,同时将spider中的请求队列改为只向一个地址发送请求,测试下载DELAY
|
|
响应间隔为10秒,貌似设置的DELAY没起作用的样子。
其实不然,这里存在一个误区,由于平时正常访问网站几乎是秒回响应,DELAY时间远大于从请求到返回响应的这段时间,所以看不出端倪。
而这里服务器的处理时间为10秒,大于DELAY时间。假设将请求到响应的完整流程看做一个事务,DOWNLOAD_DELAY并没有作用到这个完整事务上,而是作用到了每个请求上,在每个请求发送之后,DELAY即开始计数,计数到设置的DELAY时间点,发送下一个请求。
这里的DELAY时间为5秒,虽然在响应未返回就计数完成,可以发送请求,但由于并发数为1,所以只能等待收到响应后再发送下一次的请求。
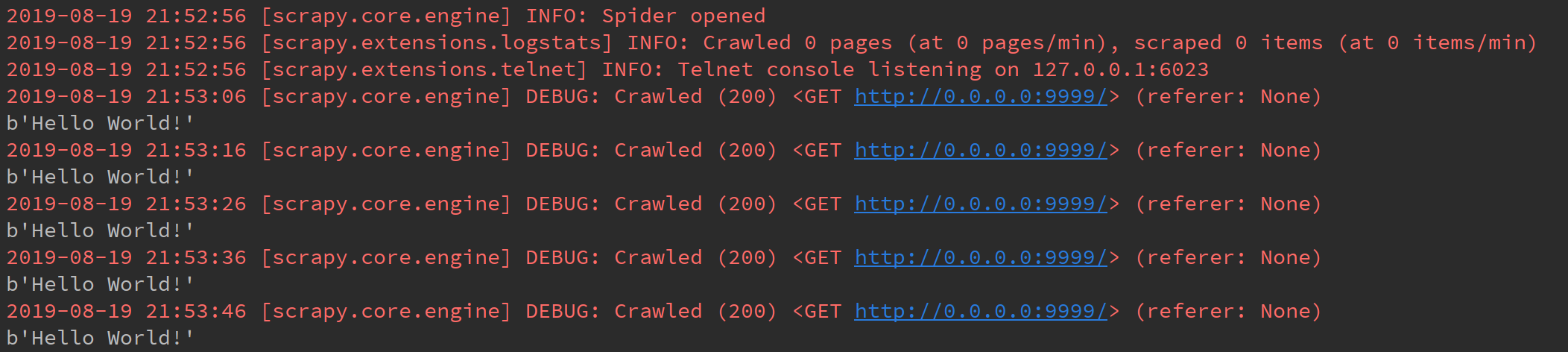
设置大于服务器处理时间的DELAY,测试下载DELAY
|
|

证实了上面的结论,在21:48:05发送第一个请求后,即开始计数,设置的DELAY为13秒,因此到21:48:18发送下一个请求,21:48:28收到响应,以此类推…
开启并发,请求队列变成对两个地址的请求,测试下载DELAY
|
|
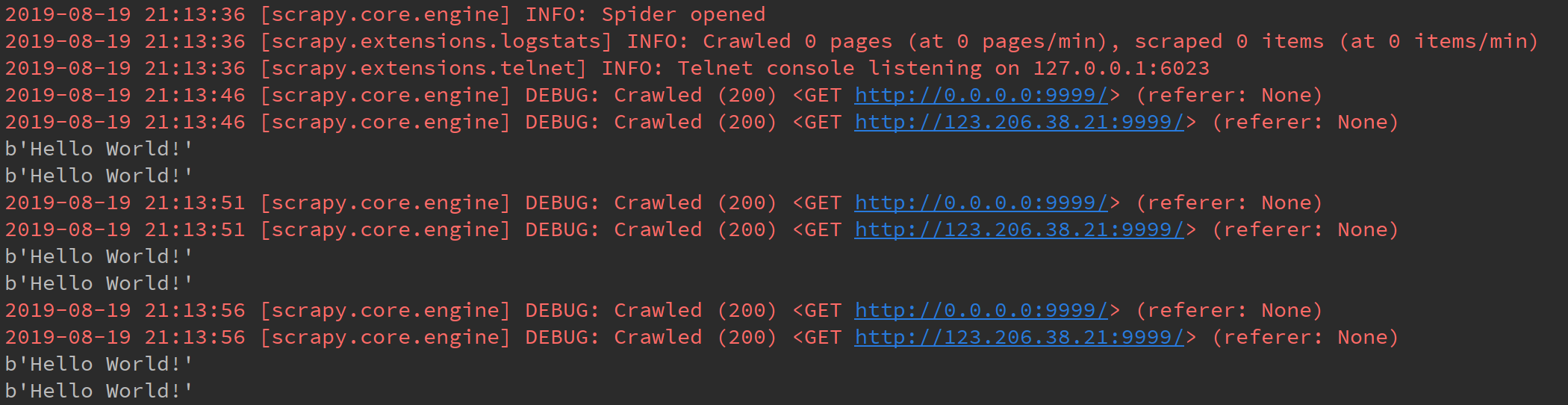
在第一个响应之后,每隔5秒收到一个响应。验证了上一步的结论,在发送请求后即开始DELAY计数,到达设定的时间后就会发送下一个请求。
两个地址的响应是同时返回的,也就是说DOWNLOAD_DELAY 针对的是单个域名的请求,而不是将所有请求一视同仁的DELAY。
总结
- 在同时设置
CONCURRENT_REQUESTS和CONCURRENT_REQUESTS_PER_DOMAIN时,两者不存在覆盖关系,而是共同对并发数起到了限制,两者的交集决定了最大并发数。 DOWNLOAD_DELAY只作用于单个地址下的请求,进行DELAY;下载间隔在发送请求后即开始计数,到达设定值发送下一次请求,无关响应。
Author bjjdkp
LastMod 2019-08-19